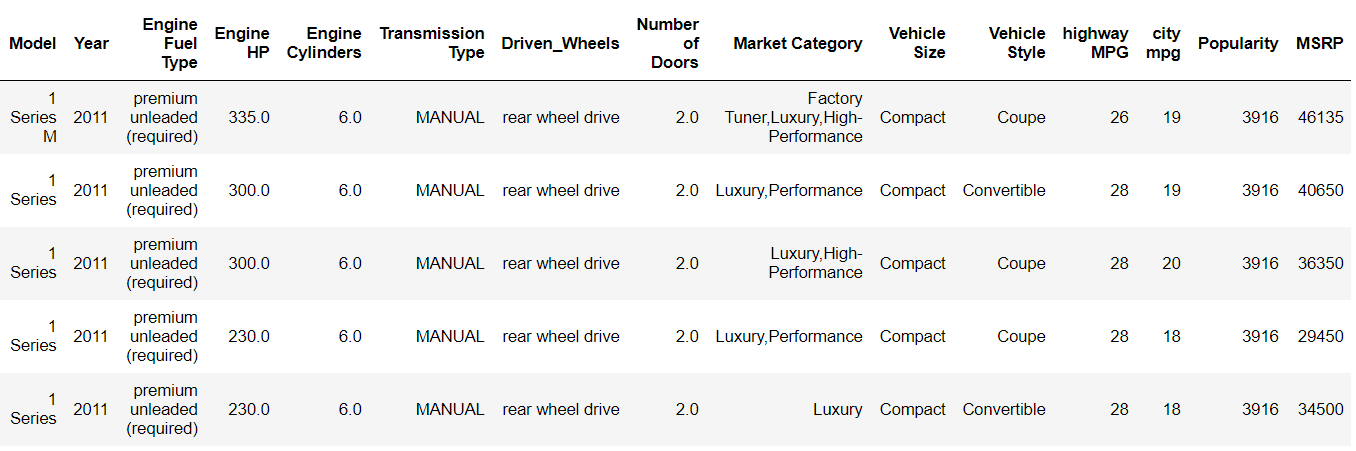
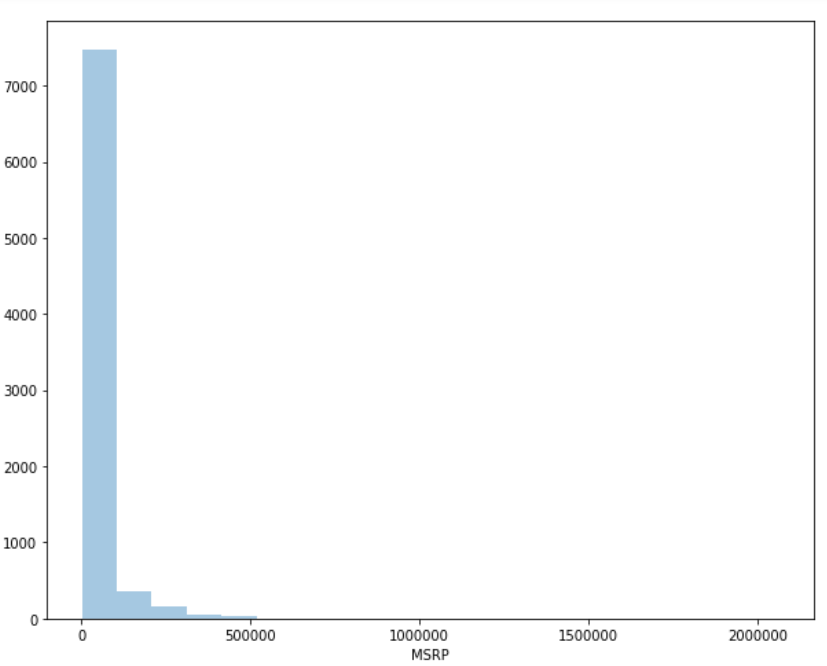
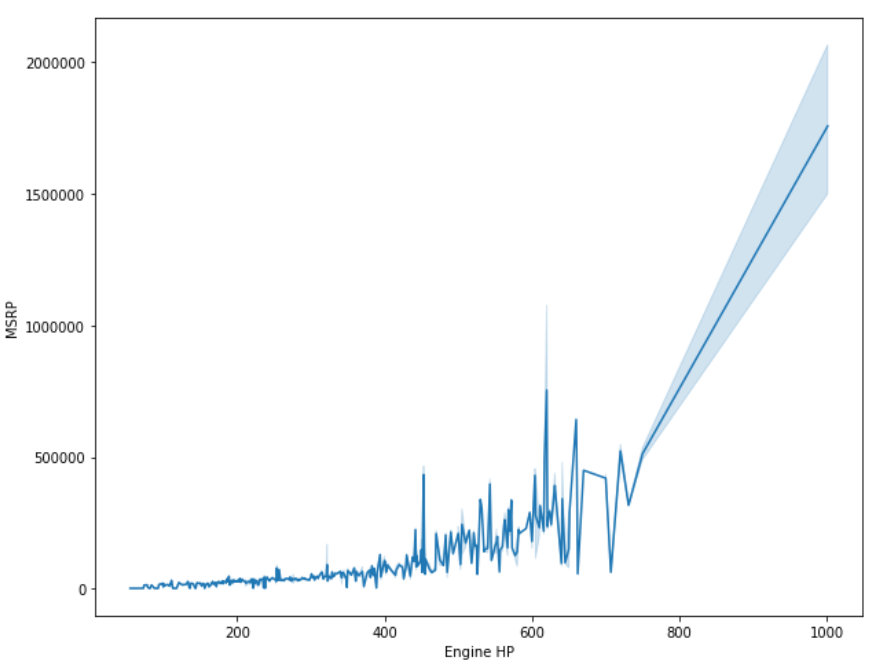
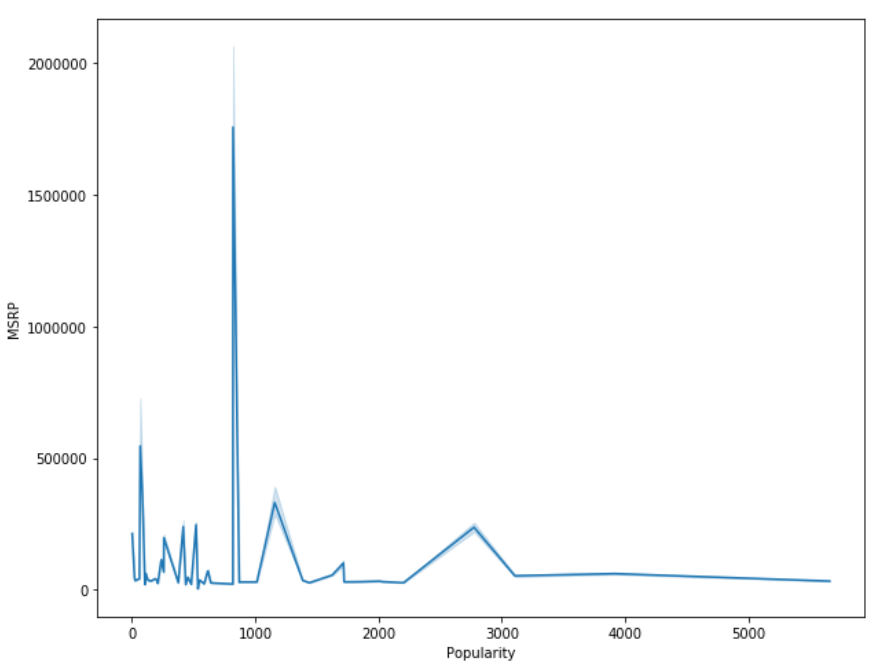
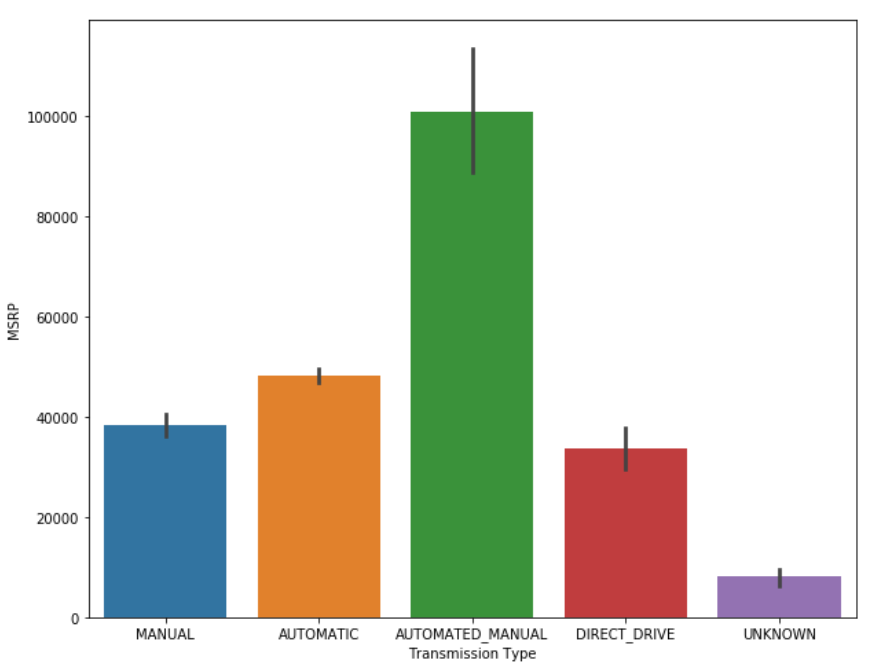
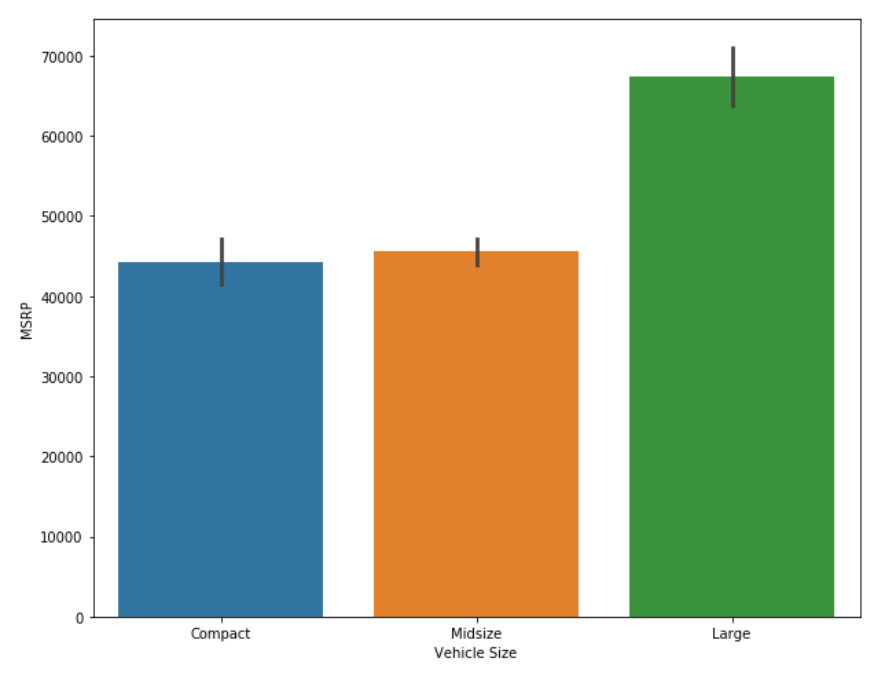
However, there are still cases where traditional machine learning algorithms are significantly ahead of artificial neural networks. Particularly in the case of smaller datasets, machine learning techniques are still handsomely outperforming the deep learning approaches.